Week starting 07/08/19 (Week 6)
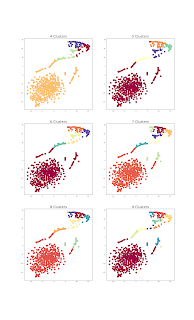
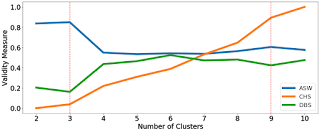
This week I started to cluster the data in order to determine where there will most likely be similarities. I have used both Umap and Tsne in combination with Kmeans prediction. The next step is to use cluster validity metrics such as Associated Silhouette Width in order to determine which cluster is best for the given data. Below are the results of Tsne (top) and Umap (bottom). In addition to this, work is being done with the distance measures that were described before.



Comments
Post a Comment